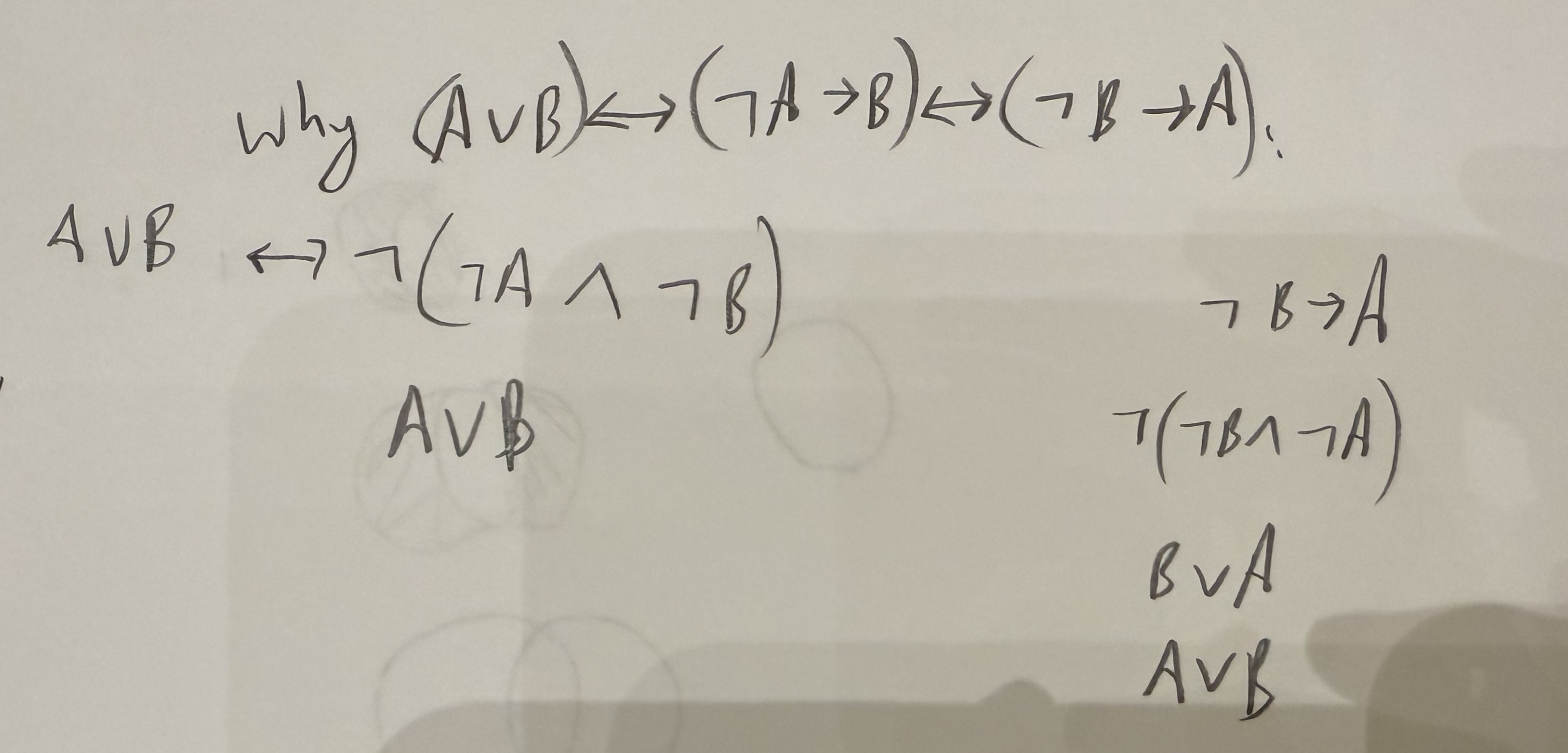Mathematical Foundations of Computing
Computability Theory
-
Turing Machine
-
Church–Turing thesis: a Turing machine can simulate every effective form of computation.
- In other words, no computation can be more effective than a Turing machine.
-
Terminology
-
(accepts, rejects, loops) on a string
-
halts - accepts or rejects (does not loop)
-
does not accept - rejects or loops
-
-
Decider - TM will always halt, never loops
-
Definitely accepts when and rejects when
-
mn TM always decides (never loops)
-
R - set of all languages that have a decider for it
-
if CFG then decidable
-
-
Recognizer - always accepts . Either rejects or loops on when
-
a Turing machine is a recognizer for ↔ (it will eventually accept an string ↔ )
-
mn always recognizes (always accepts when it should)
-
A Turing machine recognizes (or is a recognizer for) a language if:
-
If , eventually accepts
-
If , either rejects or loops forever
-
-
Formally,
-
Annoyingly, if you don't know if and the TM is still running, you can't tell if it loops or just needs more time
-
RE - set of all languages that have a recognizer for it
-
-
-
Context-free language is the set of strings generated by a context-free grammar
- There are nonterminal and terminal symbols
-
starting symbol - at the top left
-
Production: a rule going from nonterminal nonterminal/terminals
-
derivation - set of
- means B can be derived from A (* means multiple)
-
Myhill–Nerode Theorem - if is a language and is a distinguishing set of with infinitely many strings then is nonregular
-
Distinguishability - two strings and in are distinguishable () if and (e.g., , , and ) for some string
-
Formally,
-
Layman: Distinguishable if there is a string w you can add to one that will make it accepting but adding w to the other will make it rejected
-
Distinguishing set - set where each item is distinguishable from each other item
-
-
Constructing NFAs
- Have the NFA guess the information you want and deterministically check if it is true (guess-and-check technique)
-
Regular languages
-
Regular languages are problems that can be solved with finite memory. Nonregular languages correspond to languages that cannot be solved with finite memory, such as .
-
The following are equivalent: L is a regular language, there exists an NFA or DFA or regex called X such that (the language of X is L)
-
-
Kleene closure/star of a language L is L*, which is the set of all strings that can be formed by concatenating any number of strings in L (e.g., L={a,b} means L*={ε, a, b, aa, ab, ba, bb, aaa, ...})
- Formally,
-
Closure properties of languages. If and are regular languages, so are these:
-
Language concatenation is the language
- xy is the strings x and y concatenated
-
Finite automaton - collection of states joined by transitions, has a start state
-
Some states are accepting states. If automaton ends at accepting state, it accepts the input else rejects the input
-
DFA (Deterministic Finite Automaton) - exactly 1 transition at each state for each symbol in
-
NFA (nondeterministic finite automaton) - each state has 0 or multiple transitions
-
If there is one path that works, NFA accepts
-
Path dies if cannot move at a certain symbol
-
ε-transition - transition that doesn't consume input
-
Works by perfect positive guessing or massive parallelism
-
the term
nondeterministicmeans the automaton has a finite number of choices (possibly 0) to make at a given point
-
-
Subset construction (AKA powerset construction) is a method for turning an NFA into a DFA
-
A language is regular if there is a DFA D (or NFA) such that , in which case D
recognizesL
-
-
Language - string[]
string - character[]
alphabet - set<character>
-
(formal) language - set of strings
-
language over if is set of strings each over
-
is the set of all strings composed from letters in
-
-
String
-
empty string -
-
String over - finite sequence of characters from (such as aaaabbaba for )
-
-
Alphabet - set of characters
-
Characters
-
-
Automaton - mathematical model of a computer (abstraction of real computer)
-
states linked by transitions
Discrete Math
-
Induction
-
P(0) is true - basis/base case
-
P(k) → P(k+1) - inductive step
- P(k) - inductive hypothesis
-
To prove
-
-
Pigeonhole principle
-
if items are put into containers, with , then at least one container must contain more than one item
-
Generalized pigeonhole principle (AKA strong pigeonhole principle)
-
For p pigeons and h holes,
-
some crowded hole will have at least pigeons in it
-
not all holes can have more than pigeons in them
- some hole will have or fewer pigeons
-
-
-
-
is the graph complement of . All edges are turned into not edges and all not edges are turned into edges in .
-
subset symbols
-
- proper/strict subset. Cannot be itself.
-
- subset or equal
- includes the improper subset case in which a set is the (improper) subset of itself
-
is ambiguous (could mean or in different textbooks)
-
-
Generalized pigeonhole principle
-
For p pigeons and h holes,
-
some hole will have at least pigeons in it
-
some hole will have at most pigeons in it
-
-
-
The "composition of f and g" is
-
Translating first-order logic to English in a proof:
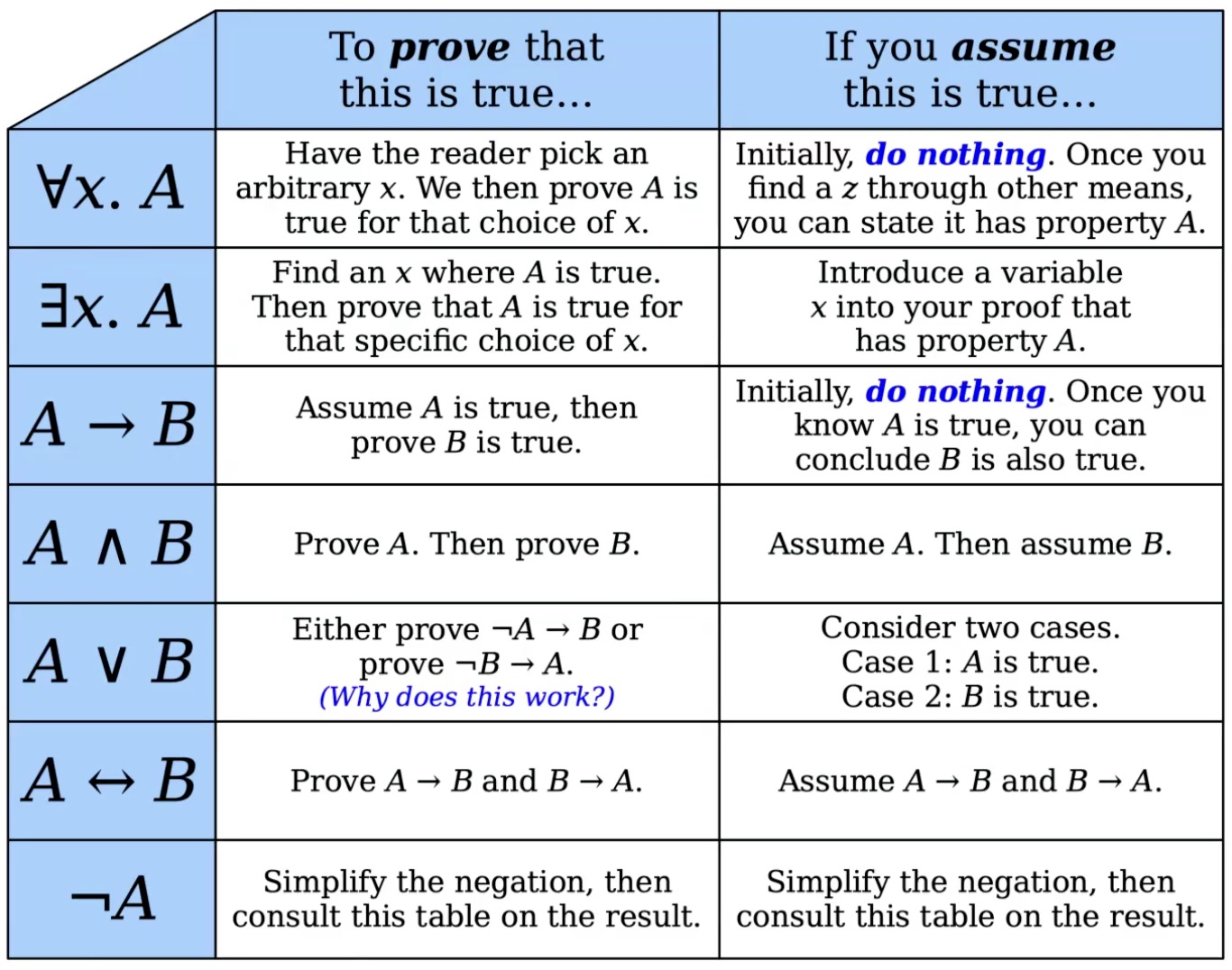
-
Functions
-
domain - function defined for every element of domain
-
codomain - output is always in codomain. Not all els in codomain must have an associated output of the f tho
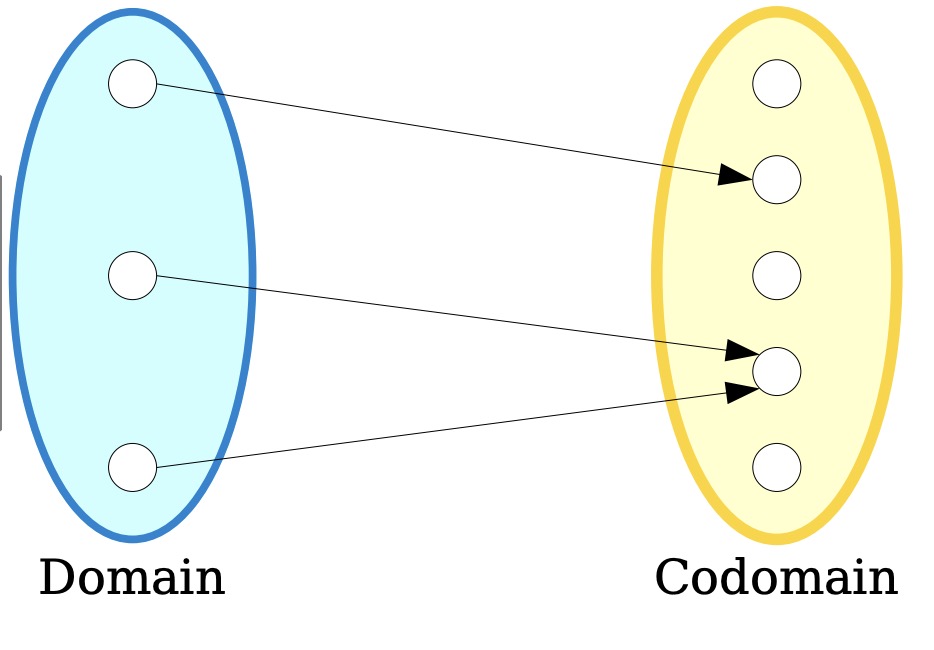
-
means f has domain A and codomain B
-
Involution: a function f is an involution if
- Layman: apply twice gives same thing back. f is an involution if f(f(x))=x
-
Surjective:
- Layman: all outputs have an input that points to it
-
Injective:
-
Equivalently
-
Layman: one-to-one function. No no output maps to two inputs. Every output maps to 1 or 0 inputs.
-
one-to-one function (not every codomain element needs to be used)
-
horizontal line test in y=f(x) tells you if a function is injective
-
-
-
Said differently, surjective associates each codomain element with at least one domain element and injective associates each codomain element with at most one domain element
-
bijective - injective and surjective, one-to-one correspondence (ever codomain element used)
-
Function needs to be:
-
- total
-
Defined on every element in domain, as opposed to partial, which means that f(a) is undefined for some a in the domain
- Partial -
-
-
- deterministic (same input always produces same output)
-
-
-
Proof explains why theorem is true
Disproof explains why claim is false (such as through a counterexample)
-
Transformations
-
-
-
(De Morgan's Law)
-
(De Morgan's Law)
-
-
-
Mnemonics
-
"Pushing" inward and flipping between operators (or vice versa):
-
to
-
to
-
-
De Morgan's Law is like distributing the and flipping the operator (from to or vice versa)
-
When applying to the biconditional () negate either side and keep the operator same
-
is the same as
- only false when p is true and q is false
-
-
Others
- same as
-
-
The Aristotelian Forms
-
All As are Bs:
-
No As are Bs:
-
Some As are Bs:
-
Some As aren't Bs:
-
-
First-order logic
-
Terms
-
Functions - object → object
Predicate - object → bool
-
Connective - bool(s) → bool
-
conjunction - (binary)
-
disjunction -
-
implication -
-
biconditional -
-
negation - (unary)
-
truth - (nullary)
-
falsity -
-
-
Quantifier - bool → bool
-
-
Examples
-
= operates on objects, operates on predicates
-
Some P is a Q translates to
-
All Ps are Qs translates to
-
-
Try to pair with and with
-
-
Precedence (highest to lowest)
-
-
and
-
(and before or)
-
-
- is right-associative so is . Most operators like are left-associative.
-
-
-
Propositional logic
-
Propositional variable
-
Propositional connectives
-
-
Universal statement - for all x, some [property] holds for x (mn works on x universally)
-
Existential statement - there is some x where [property] holds for x (mn some x exists for it to work)
-
Proof types
-
Implication: If antecedent, then consequent.
-
Assume step: assume the antecedent is true
-
Want-to-show steps
-
demonstrate that the consequent is true
-
Reiterate what you wanted to show
-
-
Derivations
Myhill-Nerode Theorem
Myhill–Nerode Theorem: if L is a language and S is a distinguishing set for that contains infinitely many strings then is nonregular.
Proof: Pick an arbitrary language and a distinguishing set for that contains infinitely many strings. We want to show that is nonregular. To do so, assume for the sake of contradiction that is regular. This means that there exists a DFA D such that . Let be the number of states in . Pick strings from . Since we picked strings and there are states in the DFA, there must be one state with strings and . Since is a distinguishing set, and cannot map to the same state of a DFA. We have reached a contradiction, so our earlier assumption must have been false. Therefore, is nonregular.

De Morgan's Laws